
Lately, we have been working at Preste on a project where we needed to build a computer vision solution for real-time processing and tracking of fast-moving objects. We used a 120 frames per second video camera and chose the NVidia Jetson TX2 platform to host our solution. As our algorithm strongly depended on fast tracking/detection capabilities there was a need for an efficient and fast deep neural network. In this post, we would like to share with you how we succeded in optimizing a specific deep network for real-time performance using a TensorRT programming framework for optimizations.
Ubuntu installation on TX2
We used SDK-manager for the software installation, JetPack 4.4 and Tensorflow 1.15.0 alongside with Tensorflow-GPU 1.15.2 (in TF >=2.0 there is no need for Tensorflow-GPU anymore) to prepare the Jetson TX2. You can find installed software specifications inside the SDK-manager. You should also be aware that TX2 has a separate, independent video encoding/decoding chip, which is very useful if you are going to work with video streaming or processing.
Implementing TensorRT
TensorRT is a programming framework which allows efficient model optimization, like layer fusion, variable type change for DNN. It is a hardware-dependent framework - it means that you cannot create an optimized model with a given system configuration and use it for another configuration. On the other end, for a targeted hardware setup, you can get x4 or even x5 inference acceleration versus non-optimized Tensorflow implementation. You can find additional information about the framework here or at the developer’s official website.
Another benefit of using TensorRT is that it has an integrated interface for TensorFlow. It is a kind of integrated semi-framework for acceleration within Tensorflow session enabling the usage of TensorRT optimized operators, engines and segments mixed with Tensorflow nodes. Here you can find an introduction to the TF-TRT. Any additional info about the relations between Tensorflow and TensoRT can also be found in the official documentation.
For our project, we created a UNET-like segmentation network with fewer parameters and a slightly different architecture than the original one. It was changed to cover specific project needs. In our case, TensorRT could not properly convert this model to a standalone TensorRT plan for inference on the CUDA engine. Our model had a complex branching and some specific paddings not supported by TensorRT. We also chose not to drift too far away from Tensorflow, so we decided to implement a TF-TRT mixed optimization.
Workflow
Freezing
We work with a frozen graph from the start. It is important to “freeze” the graph properly:
Remove/disable unused nodes
Change the train state in some nodes, set the “BatchNorm” to “False” condition...
Remove/fuse duplicated nodes
Fold constant nodes and fold batch normalization if possible
All these procedures will probably decrease the number of your nodes (in our case, from 275 to 209). You can find the code example below:
def freeze_and_optimize(session, keep_var_names=None, input_names=None, output_names=None, clear_devices=True):
graph = session.graph
with graph.as_default():
freeze_var_names = list(set(v.op.name for v in tf.global_variables()).difference(keep_var_names or []))
output_names += [v.op.name for v in tf.global_variables()]
input_graph_def = graph.as_graph_def()
if clear_devices:
for node in input_graph_def.node:
node.device = ""
graph = tf.graph_util.remove_training_nodes(
input_graph_def, protected_nodes=output_names)
graph = tf.graph_util.convert_variables_to_constants(
session, graph, output_names, freeze_var_names)
transforms = [
'remove_nodes(op=Identity)',
'merge_duplicate_nodes',
'strip_unused_nodes',
'fold_constants(ignore_errors=true)',
'fold_batch_norms',
]
graph = TransformGraph(
graph, input_names, output_names, transforms)
return graphConverting to TF-TRT optimized graph:
At this stage, we need to tune conversion parameters, otherwise converter methods can miss optimization of some parts of the computation graph. If parameters are not suitable, the converter itself will fail to optimize the graph correctly or not optimize it at all.
The optimized graph will run inside the Tensorflow session, it will not be as fast as a pure TensorRT plan, but still much faster than the unoptimized Tensorflow graph.
It is very convenient that Tensorflow supports integration with TensorRT because Tensorflow can avoid pit optimization: if an optimizer method has found parts of the computational graph that cannot be optimized, the optimizer will just leave it and mark it for Tensorflow inferencing. Other optimizations will be computed by TensorRT.
If we look at the model via Tensorboard, we can see that the graph has reduced size, some nodes are fused/changed to "TRTEngineOP", "_ReLUTRT", "TRTEngineOP_native_segment", etc.
Examples: parts of the computation graph before and after :
Before :

After :

Here is a code with the TensorRT conversion and description:
from tensorflow.python.compiler.tensorrt import trt_conver as trt
with tf.Session() as sess:
with tf.gfile.GFile("frozen_graph.pb", "rb") as f:
frozen_graph = tf.GraphDef()
frozen_graph.ParseFromString(f.read())
converter = trt.TrtGraphConverter(inpup_graph_def=frozen_graph,
max_workspace_size_bytes = 1 << 32,
precision_mode='FP16',
minimum_segment_size=5,
max_batch_size = 1,
is_dynamic_op=False,
nodes_blacklist=[OUTPUT_NODES])
trt_graph = converter.convert()
graph_io.write_graph(trt_graph, save_pb_dir, “trt_{}_optimized.pb”.format(model_name[:-3]), as_text=False)max_workspace_size_bytes - allocated memory on the device to execute TensorRT algorithms. If you allocate insufficient space, execution will fail with an error, or you will get no acceleration. It depends on the number of segments, their size and the number of engines. You can pick this parameter iteratively. Our choice was 1 << 32 bytes.
precision_mode - variable type that is used in engines and segments.
minimum_segment_size - sets how many TF nodes can be packed into the TensorRT optimized segment.
max_batch_size - number of images to feed on input. It also defines the particular size of the input shape.
is_dynamic_op - dynamic input shape, it will create cached engines with different input shapes for different input values. The number of engines can be controlled by the max_cached_engines parameter.
nodes_blacklist - selected nodes to avoid conversion: output nodes or others.
Inference:
gd = tf.GraphDef()
with tf.gfile.GFile("trt_optimized_graph.pb", "rb") as f:
gd.ParseFromString(f.read())
graph = tf.Graph()
with graph.as_default():
net_inp, net_out = tf.import_graph_def(gd, return_elements=[INPUT_NODE, OUTPUT_NODES])
sess_config = tf.ConfigProto()
sess_config.gpu_options.allow_growth = True
sess_config.allow_soft_placement = True
with tf.Session(graph=graph, config=sess_config) as sess:
sess.run(net_out, feed_dict={net_inp:image})As we can see the pipeline remains simple and it is still Tensorflow. Using this approach, we reached 95-110 frames per second where the non-optimized model had 5-25 frames per second, as illustrated in the plots below :
Non optimized:
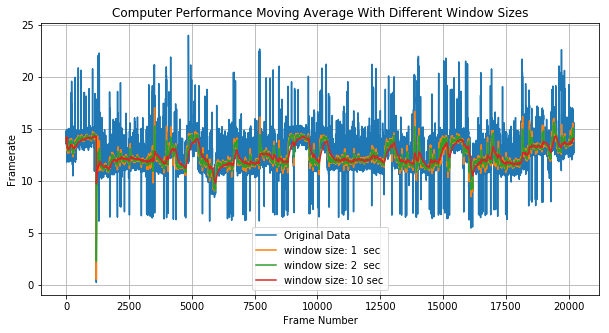
Optimized:

Hardware tips:
NVidia Jetson TX2 uses shared memory: you should keep some part of it free, otherwise the system may crash (confirmed experimentally, solved by JetPack reinstallation) and it can slightly slow your model even if you have turned on reallocation flag in device settings for Tensorflow inference.
Turn on the FAN: TX2 module is very sensitive to temperature changes, so you should keep it cool.
All performance tests were done at MAXP Core ARM power mode: it is an electricity consumption plan for maximum performance.
Conclusions
For our project, the TF-TRT approach gave the best and fastest optimization results and we were able to increase the frame rate of our overall solution by 2.7 times compared to other approaches. We appreciated the flexibility and efficiency of this approach, such as allowing us to avoid pits like a pure conversion.
In the second part of this article (to be issued), we will show the results obtained with a well-optimized TensorRT standalone plan file that can be run on CUDA devices, overcoming the issues created by attempting to pad layers of different sizes during concatenation. We will also go deeper into the usage of TensorRT API, showing the details of layer redefinition inside the API. We will show how we leveraged the GraphSurgeon layer execution. We will also evoke the usage of JetsonUtils for live streaming processing and present a comparison between TX2 and Xavier for our project.
--------------------------------
* Follow us on LinkedIn for next blog updates:
* Interested in our skills? Let's discuss your projects together:

or
* Our public Github repository:

--------------------------------
References
Roman Sokolow: article about custom TensorRT layer creation inside C++ API
Xiaowei Wan: webinar dedicated to the best practices for the TF-TRT framework
Git repository with the code for freezing and optimizing Tensorflow tools via the TF-TRT interface
Comments